Steerable Pyramid
This tutorial walks through the basic features of the torch implementation of the Steerable Pyramid included in plenoptic, and as such describes some basic signal processing that may be useful when building models that process images. We use the steerable pyramid construction in the frequency domain, which provides perfect reconstruction (as long as the input has an even height and width, i.e., 256x256 not 255x255) and allows for any number of orientation bands. For more details on
steerable pyramids and how they are built, see the pyrtools tutorial at: https://pyrtools.readthedocs.io/en/latest/.
Here we will specifically focus on the specifics of the torch version and how it may be used in concert with other differentiable torch models.
[1]:
import numpy as np
import torch
# this notebook uses torchvision, which is an optional dependency.
# if this fails, install torchvision in your plenoptic environment
# and restart the notebook kernel.
try:
import torchvision
except ModuleNotFoundError:
raise ModuleNotFoundError("optional dependency torchvision not found!"
" please install it in your plenoptic environment "
"and restart the notebook kernel")
import torchvision.transforms as transforms
import torch.nn.functional as F
from torch import nn
import matplotlib.pyplot as plt
import pyrtools as pt
import plenoptic as po
%matplotlib inline
from plenoptic.simulate import SteerablePyramidFreq
from plenoptic.synthesize import Eigendistortion
from plenoptic.tools.data import to_numpy
dtype = torch.float32
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
import os
from tqdm.auto import tqdm
%load_ext autoreload
%autoreload 2
Introduction: Steerable Pyramid Wavelets
In this section we will:
Visualize the wavelets that produce steerable pyramid coefficients
Visualize the steerable pyramid decomposition for two example images
Provide some technical details about this steerable pyramid implementation and how it may differ from others
Visualizing Wavelets
Many modern computer vision algorithms employ convolution: a kernel slides across an image, taking inner products along the way. Thus the output of a convolution at a given location is the similarity between the kernel and the image content at that location, and therefore if your kernel has a low-spatial frequency it will function as a low-pass filter. Of course, low-pass filtering has a very simple interpretation in the fourier domain (simply attenuate the high spatial frequencies and leave low spatial frequencies unchanged). This particular scenario belies a more general fact: convolution in the spatial domain is mathematically equivalent to multiplication in the Fourier domain (a result known as the convolution theorem). Though both are equivalent there may be advantages to carrying out the operation in one domain or the other. This implementation of the steerable pyramid operates in the Fourier domain. For those that are interested, the first benefit of this implementation is that we have access to a perfectly invertible representation (i.e. the representation can be inverted to reconstruct the input perfectly and therefore, one can analyze how perturbations to the representation are visualized in the input space). Second, working in the Fourier domain, allows us to work with a complex-valued representation which can provide natural benefits like being able to construct quadrature pair filters etc. easily.
Because of this we don’t have direct access to a set of spatial filters for visualization, however we can generate the equivalent spatial filters by inverting a set of coefficients (i.e., output of the pyramid) constructed to contain zero everywhere except in the center of a single band. Below we do this to visualize the filters for a 3 scale 4 orientation steerable pyramid.
[2]:
order = 3
imsize = 64
pyr = SteerablePyramidFreq(height=3, image_shape=[imsize, imsize], order=order).to(device)
empty_image = torch.zeros((1, 1, imsize, imsize), dtype=dtype).to(device)
pyr_coeffs = pyr.forward(empty_image)
# insert a 1 in the center of each coefficient...
for k,v in pyr.pyr_size.items():
mid = (v[0]//2, v[1]//2)
pyr_coeffs[k][0, 0, mid[0], mid[1]] = 1
# ... and then reconstruct this dummy image to visualize the filter.
reconList = []
for k in pyr_coeffs.keys():
# we ignore the residual_highpass and residual_lowpass, since we're focusing on the filters here
if isinstance(k, tuple):
reconList.append(pyr.recon_pyr(pyr_coeffs, [k[0]], [k[1]]))
po.imshow(reconList, col_wrap=order+1, vrange='indep1', zoom=2);

We can see that this pyramid is representing a 3 scale 4 orientation decomposition: each row represents a single scale, which we can see because each filter is the same size. As the filter increases in size, we describe the scale as getting “coarser”, and its spatial frequency selectivity moves to lower and lower frequencies (conversely, smaller filters are operating at finer scales, with selectivity to higher spatial frequencies). In a given column, all filters have the same orientation: the first column is vertical, the third horizontal, and the other two diagonals.
Visualizing Filter Responses (Wavelet Coefficients)
Now let’s see what the steerable pyramid representation for images look like.
Like all models included in and compatible with plenoptic, the included steerable pyramid operates on 4-dimensional tensors of shape (batch, channel, height, width). We are able to perform batch computations with the steerable pyramid implementation, analyzing each batch separately. Similarly, the pyramid is meant to operate on gray-scale images, and so channel > 1 will cause the pyramid to run independently on each channel (meaning each of the first two dimesions are treated
effectively as batch dimensions).
[3]:
im_batch = torch.cat([po.data.curie(), po.data.reptile_skin()], axis=0)
print(im_batch.shape)
po.imshow(im_batch)
order = 3
dim_im = 256
pyr = SteerablePyramidFreq(height=4, image_shape=[dim_im, dim_im], order=order).to(device)
pyr_coeffs = pyr(im_batch)
torch.Size([2, 1, 256, 256])

By default, the output of the pyramid is stored as a dictionary whose keys are either a string for the 'residual_lowpass' and 'residual_highpass' bands or a tuple of (scale_index, orientation_index). plenoptic provides a convenience function, pyrshow, to visualize the pyramid’s coefficients for each image and channel.
[4]:
print(pyr_coeffs.keys())
po.pyrshow(pyr_coeffs, zoom=0.5, batch_idx=0);
po.pyrshow(pyr_coeffs, zoom=0.5, batch_idx=1);
odict_keys(['residual_highpass', (0, 0), (0, 1), (0, 2), (0, 3), (1, 0), (1, 1), (1, 2), (1, 3), (2, 0), (2, 1), (2, 2), (2, 3), (3, 0), (3, 1), (3, 2), (3, 3), 'residual_lowpass'])


For some applications, such as coarse-to-fine optimization procedures, it may be convenient to output a subset of the representation, including coefficients from only some scales. We do this by passing a scales argument to the forward method (a list containing a subset of the values found in pyr.scales):
[5]:
#get the 3rd scale
print(pyr.scales)
pyr_coeffs_scale0 = pyr(im_batch, scales=[2])
po.pyrshow(pyr_coeffs_scale0, zoom=2, batch_idx=0);
po.pyrshow(pyr_coeffs_scale0, zoom=2, batch_idx=1);
['residual_lowpass', 3, 2, 1, 0, 'residual_highpass']

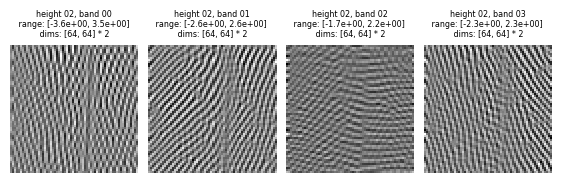
The above pyramid was the real pyramid but in many applications we might want the full complex pyramid output ). This can be set using the is_complex argument. When this is true, the pyramid uses a complex-valued filter, resulting in a complex-valued output. The real and imaginary components can be understood as the outputs of filters with identical scale and orientation, but different phases: the imaginary component is phase-shifted 90 degrees from the real (we refer to this matched pair of
filters as a “quadrature pair”). This can be useful if you wish to construct a representation that is phase-insensitive (as complex cells in the primary visual cortex are believed to be), which can be done by computing the amplitude / complex modulus (e.g., call torch.abs(x)). po.simul.rectangular_to_polar and po.simul.rectangular_to_polar_dict provide convenience wrappers for this functionality.
See A Parametric Texture Model Based on Joint Statistics of Complex Wavelet Coefficients for more technical details.
[6]:
order = 3
height = 3
pyr_complex = SteerablePyramidFreq(height=height, image_shape=[256,256], order=order, is_complex=True)
pyr_complex.to(device)
pyr_coeffs_complex = pyr_complex(im_batch)
[7]:
# the same visualization machinery works for complex pyramids; what is shown is the magnitude of the coefficients
po.pyrshow(pyr_coeffs_complex, zoom=0.5, batch_idx=0);
po.pyrshow(pyr_coeffs_complex, zoom=0.5, batch_idx=1);


Now that we have seen the basics of using the pyramid, it’s worth noting the following: an important property of the steerable pyramid is that it should respect the generalized parseval theorem (i.e. the energy of the pyramid coefficients should equal the energy of the original image). The matlabpyrtools and pyrtools versions of the SteerablePyramid DO NOT respect this, so in our
version, we have provided a fix that normalizes the FFTs such that energy is preserved. This is set using the tight_frame=True when instantiating the pyramid; however, if you require matching the outputs to the matlabPyrTools or PyrTools versions, please note that you will need to set this argument to False.
Putting the “Steer” in Steerable Pyramid
As we have seen, steerable pyramids decompose images into a fixed set of orientation bands (at several spatial scales). However given the responses at this fixed set of orientation bands, the pyramid coefficents for any arbitrary intermediate orientation can be calculated from a linear interpolation of the original bands. This property is known as “steerability.” Below we steer a set of coefficients through a series of angles and visualize how the represeted features rotate.
[8]:
# note that steering is currently only implemeted for real pyramids, so the `is_complex` argument must be False (as it is by default)
pyr = SteerablePyramidFreq(height=3, image_shape=[256,256], order=3, twidth=1).to(device)
coeffs = pyr(im_batch)
# play around with different scales! Coarser scales tend to make the steering a bit more obvious.
target_scale = 2
N_steer = 64
M = torch.zeros(1, 1, N_steer, 256//2**target_scale, 256//2**target_scale)
for i, steering_offset in enumerate(np.linspace(0, 1, N_steer)):
steer_angle = steering_offset * 2 * np.pi
steered_coeffs, steering_weights = pyr.steer_coeffs(coeffs, [steer_angle]) # (the steering coefficients are also returned by pyr.steer_coeffs steered_coeffs_ij = oig_coeffs_ij @ steering_weights)
M[0, 0, i] = steered_coeffs[(target_scale, 4)][0, 0] # we are always looking at the same band, but the steering angle changes
po.tools.convert_anim_to_html(po.animshow(M, framerate=6, repeat=True, zoom=2**target_scale))
[8]:
Example Application: Frontend for Convolutional Neural Network
Until now we have just seen how to use the Steerable Pyramid as a stand-alone fixed feature extractor, but what if we wanted to use it in a larger model, as a front-end for a deep CNN or other model? The steerable pyramid decomposition is qualitatively similar to the computations in primary visual cortex, so it stands to reason that using a steerable pyramid frontend might serve as an inductive bias that encourages subsequent layers to have more biological structure. In the literature it has been demonstrated that using a V1-like front end attached to a CNN trained on classification can lead to improvements in adversarial robustness Dapello et. al, 2020.
In this section we will demonstrate how the plenoptic steerable pyramid can be made compatible with standard deep learning architectures and use it as a frontend for a standard CNN.
Preliminaries
Most standard model architectures only accept channels with fixed shape, but each scale of the pyramid coefficients has a different shape (because each scale is downsampled by a factor of 2). In order to obtain an output amenable to downstream processing by standard torch nn modules, we have created an argument to the pyramid (downsample=False) that does not downsample the frequency masks at each scale and thus maintains output feature maps that all have a fixed size. Once you have done
this, you can then convert the dictionary into a tensor of size (batch, channel, height, width) so that it can easily be passed to a downstream nn.Module. The details of how to do this are provided in the the convert_pyr_to_tensor function within the SteerablePyramidFreq class. Let’s try this and look at the first image both in the downsampled and not downsampled versions:
[9]:
height = 3
order = 3
pyr_fixed = SteerablePyramidFreq(height=height, image_shape=[256,256], order=order, is_complex=True,
downsample=False, tight_frame=True).to(device)
pyr_coeffs_fixed, pyr_info = pyr_fixed.convert_pyr_to_tensor(pyr_fixed(im_batch), split_complex=False)
# we can also split the complex coefficients into real and imaginary parts as separate channels.
pyr_coeffs_split, _ = pyr_fixed.convert_pyr_to_tensor(pyr_fixed(im_batch), split_complex=True)
print(pyr_coeffs_split.shape, pyr_coeffs_split.dtype)
print(pyr_coeffs_fixed.shape, pyr_coeffs_fixed.dtype)
torch.Size([2, 26, 256, 256]) torch.float32
torch.Size([2, 14, 256, 256]) torch.complex64
We can see that in this complex pyramid with 4 scales and 3 orientations there will be 26 channels: 4 scales x 3 orientations x 2 (for real and imaginary featuremaps) + 2 (for the residual bands). NOTE: you can change what scales/residuals get included in this output tensor again using the scales argument to the forward method.
In order to display the coefficients, we need to convert the tensor coefficients back to a dictionary. We can do this either by directly accessing the dictionary version (through the pyr_coeffs attribute in the pyramid object) or by using the internal convert_tensor_to_pyr function. We can check that these are equal.
[10]:
pyr_coeffs_fixed_1 = pyr_fixed(im_batch)
pyr_coeffs_fixed_2 = pyr_fixed.convert_tensor_to_pyr(pyr_coeffs_fixed, *pyr_info)
for k in pyr_coeffs_fixed_1.keys():
print(torch.allclose(pyr_coeffs_fixed_2[k], pyr_coeffs_fixed_1[k]))
True
True
True
True
True
True
True
True
True
True
True
True
True
True
/home/billbrod/Documents/plenoptic/src/plenoptic/simulate/canonical_computations/steerable_pyramid_freq.py:476: UserWarning: Casting complex values to real discards the imaginary part (Triggered internally at ../aten/src/ATen/native/Copy.cpp:299.)
band = pyr_tensor[:,i,...].unsqueeze(1).type(torch.float)
We can now plot the coefficients for the not downsampled version (pyr_coeffs_complex from the last section) and the downsampled version pyr_coeffs_fixed_1 from above and see how they compare visually.
[11]:
po.pyrshow(pyr_coeffs_complex, zoom=0.5);
po.pyrshow(pyr_coeffs_fixed_1, zoom=0.5);


We can see that the not downsampled version maintains the same features as the original pyramid, but with fixed feature maps that have spatial dimensions equal to the original image (256x256). However, the pixel magnitudes in the bands are different due to the fact that we are not downsampling in the frequency domain anymore. This can equivalently be thought of as the inverse operation of blurring and downsampling. Therefore the upsampled versions of each scale are not simply zero interpolated versions of the downsampled versions and thus the pixel values are non-trivially changed. However, the energy in each band should be preserved between the two pyramids and we can check this by computing the energy in each band for the two pyramids and checking if they are the same.
[12]:
# the following passes with tight_frame=True or tight_frame=False, either way.
pyr_not_downsample = SteerablePyramidFreq(height=height,image_shape=[256,256],order=order,is_complex = False,twidth=1, downsample=False, tight_frame=False)
pyr_not_downsample.to(device)
pyr_downsample = SteerablePyramidFreq(height=height,image_shape=[256,256],order=order,is_complex = False,twidth=1, downsample=True, tight_frame=False)
pyr_downsample.to(device)
pyr_coeffs_downsample = pyr_downsample(im_batch.to(device))
pyr_coeffs_not_downsample = pyr_not_downsample(im_batch.to(device))
for i in range(len(pyr_coeffs_downsample.keys())):
k = list(pyr_coeffs_downsample.keys())[i]
v1 = to_numpy(pyr_coeffs_downsample[k])
v2 = to_numpy(pyr_coeffs_not_downsample[k])
v1 = v1.squeeze()
v2 = v2.squeeze()
#check if energies match in each band between downsampled and fixed size pyramid responses
print(np.allclose(np.sum(np.abs(v1)**2), np.sum(np.abs(v2)**2), rtol=1e-4, atol=1e-4))
def check_parseval(im ,coeff, rtol=1e-4, atol=0):
'''
function that checks if the pyramid is parseval, i.e. energy of coeffs is
the same as the energy in the original image.
Args:
input image: image stimulus as torch.Tensor
coeff: dictionary of torch tensors corresponding to each band
'''
total_band_energy = 0
im_energy = im.abs().square().sum().numpy()
for k,v in coeff.items():
band = coeff[k]
print(band.abs().square().sum().numpy())
total_band_energy += band.abs().square().sum().numpy()
np.testing.assert_allclose(total_band_energy, im_energy, rtol=rtol, atol=atol)
True
True
True
True
True
True
True
True
True
True
True
True
True
True
Model Training
We are now ready to demonstrate how the steerable pyramid can be used as a fixed frontend for further stages of (learnable) processing!
[13]:
# First we define/download the dataset
train_set = torchvision.datasets.FashionMNIST(
# change this line to wherever you'd like to download the FashionMNIST dataset
root = '../data',
train = True,
download = True,
transform = transforms.Compose([
transforms.ToTensor()
])
)
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz to /home/billbrod/Documents/plenoptic/data/images/FashionMNIST/raw/train-images-idx3-ubyte.gz
100%|█████████████████████████████████████████████████████████████████| 26421880/26421880 [00:25<00:00, 1021172.29it/s]
Extracting /home/billbrod/Documents/plenoptic/data/images/FashionMNIST/raw/train-images-idx3-ubyte.gz to /home/billbrod/Documents/plenoptic/data/images/FashionMNIST/raw
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz to /home/billbrod/Documents/plenoptic/data/images/FashionMNIST/raw/train-labels-idx1-ubyte.gz
100%|████████████████████████████████████████████████████████████████████████| 29515/29515 [00:00<00:00, 316479.83it/s]
Extracting /home/billbrod/Documents/plenoptic/data/images/FashionMNIST/raw/train-labels-idx1-ubyte.gz to /home/billbrod/Documents/plenoptic/data/images/FashionMNIST/raw
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz to /home/billbrod/Documents/plenoptic/data/images/FashionMNIST/raw/t10k-images-idx3-ubyte.gz
100%|███████████████████████████████████████████████████████████████████| 4422102/4422102 [00:01<00:00, 3325433.77it/s]
Extracting /home/billbrod/Documents/plenoptic/data/images/FashionMNIST/raw/t10k-images-idx3-ubyte.gz to /home/billbrod/Documents/plenoptic/data/images/FashionMNIST/raw
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz
Downloading http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz to /home/billbrod/Documents/plenoptic/data/images/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz
100%|█████████████████████████████████████████████████████████████████████████| 5148/5148 [00:00<00:00, 6730759.66it/s]
Extracting /home/billbrod/Documents/plenoptic/data/images/FashionMNIST/raw/t10k-labels-idx1-ubyte.gz to /home/billbrod/Documents/plenoptic/data/images/FashionMNIST/raw
[14]:
# Define a simple model: SteerPyr --> ConvLayer --> Fully Connected
class PyrConvFull(nn.Module):
def __init__(self, imshape, order, scales, exclude=[], is_complex=True):
super().__init__()
self.imshape = imshape
self.order = order
self.scales = scales
self.output_dim = 20 # number of channels in the convolutional block
self.kernel_size = 6
self.is_complex = is_complex
self.rect = nn.ReLU()
self.pyr = SteerablePyramidFreq(height=self.scales,image_shape=self.imshape,
order=self.order,is_complex = self.is_complex,twidth=1, downsample=False)
# num_channels = num_scales * num_orientations (+ 2 residual bands) (* 2 if complex)
channels_per = 2 if self.is_complex else 1
self.pyr_channels = ((self.order + 1) * self.scales + 2) * channels_per
self.conv = nn.Conv2d(in_channels=self.pyr_channels, kernel_size=self.kernel_size,
out_channels=self.output_dim, stride=2)
# the input ndim here has to do with the dimensionality of self.conv's output, so will have to change
# if kernel_size or output_dim do
self.fc = nn.Linear(self.output_dim * 12**2, 10)
def forward(self, x):
out = self.pyr(x)
out, _ = self.pyr.convert_pyr_to_tensor(out)
# case handling for real v. complex forward passes
if self.is_complex:
# split to real and imaginary so nonlinearities make sense
out_re = self.rect(out.imag)
out_im = self.rect(out.real)
# concatenate
out = torch.cat([out_re, out_im], dim=1)
else:
out = self.rect(out)
out = self.conv(out)
out = self.rect(out)
out = out.view(out.shape[0], -1) # reshape for linear layer
out = self.fc(out)
return out
[15]:
# Training Pyramid Model
model_pyr = PyrConvFull([28, 28], order=4, scales=2, is_complex=False)
loader = torch.utils.data.DataLoader(train_set, batch_size = 50)
optimizer = torch.optim.Adam(model_pyr.parameters(), lr=1e-3)
epoch = 2
losses = []
fracts_correct = []
for e in range(epoch):
for batch in tqdm(loader):
images = batch[0]
labels = batch[1]
preds = model_pyr(images)
loss = F.cross_entropy(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.item())
n_correct = preds.argmax(dim=1).eq(labels).sum().item()
fracts_correct.append(n_correct / 50)
fig, axs = plt.subplots(1, 2, figsize=(10, 5))
axs[0].plot(losses)
axs[0].set_xlabel('Iteration')
axs[0].set_ylabel('Cross Entropy Loss')
axs[1].plot(fracts_correct)
axs[1].set_xlabel('Iteration')
axs[1].set_ylabel('Classification Performance')
[15]:
Text(0, 0.5, 'Classification Performance')
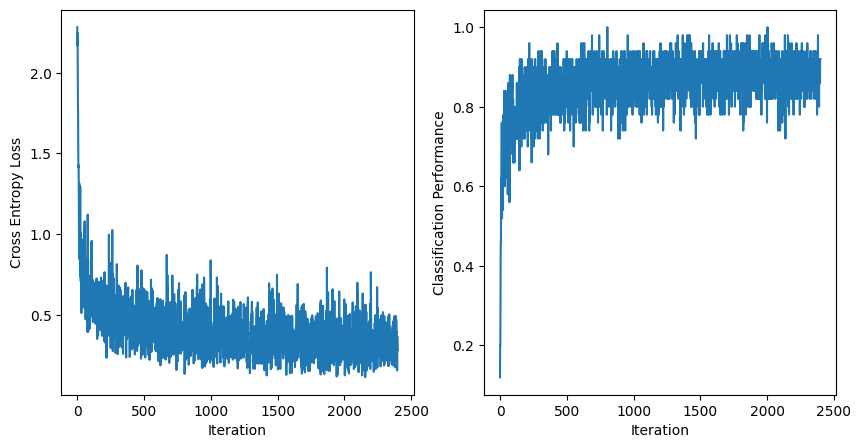
The steerable pyramid can be smoothly integrated with standard torch modules and autograd, so the impact of including such a frontend could be probed using the sythesis techniques provided by Plenoptic.